A ConvNet for the 2020s
在 2020s,ViTs,尤其是以 Swin Transformers 为代表的分层 Transformers,开始取代 CNN 成为视觉模型主干网络的首选。这篇论文 (1) 重新检视了这些分层 ViTs 的设计空间,提取对性能提升起关键作用的组件,并以此构建了一个结构简单性能优于分层 ViTs 的纯 ConvNet 模型:ConvNeXts 。
作者从不同层级探索了 Swin Transformers 的设计,以此完成一个普通 ResNet 到更现代化的 ConvNet 的改造。论文中有具体的改造轨迹,对网络结构设计有极大的参考价值,具体细节请参考原始论文。
下面是改造后的网络结构与其他网络结构的对比图:
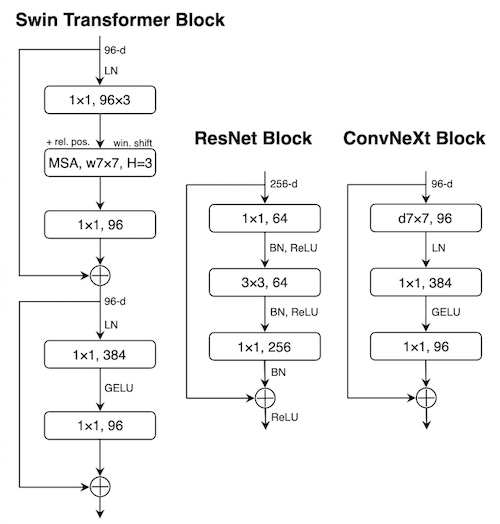
网络结构的设计既是艺术又是苦力活,真的很难把握。我现在的研究已经很少再关注网络结构的设计了。但是这些无意中设计或经过无数实验筛选出来的基础网络结构,如 ResNet 、Transformers 和这里提到的 ConvNeXt,无疑带给了深度学习领域巨大的改变。
原文写的很精彩,其中提到了卷积网络和 ViTs 各自的优势值得注意:
- ViT 的一个主要优势是其扩展行为:在更大的模型和数据集下,Transformers 的性能可以大大优于标准 ResNet。
- ConvNets 具有多个内置归纳偏置 (inductive biases),使其非常适合各种计算机视觉应用。