Improved Training and Scaling Strategies
回顾论文 (2) 里的几篇重要引用文献,简述其观察和方法。
1. EfficientNet: Rethinking Model Scaling for CNN
模型越大性能越好,但是当前的模型都只是向单个维度(深度、宽度、图片分辨率)分别扩展。这篇文章探索了向这三个维度的组合方向扩展。
该论文 (3) 有以下两点发现:
- 扩展网络宽度、深度或分辨率的任何单个维度都可以提高准确性,但准确性增益会逐渐降低。
- 这三个扩展维度并不是相互独立的,宽的网络更容易捕捉细粒度的特征,但极宽的浅网络却无法捕获高层特征。
因此,当扩展 ConvNet 时,网络的宽度、深度和图像分辨率这三个扩展维度之间的平衡至关重要,并会对模型的准确性和效率产生较大的影响。文章中提出了一种非常简单的扩展策略:用单一的复合系数 \(\phi\) 对网络的宽度、深度、输入分辨率进行均匀的缩放。具体细节参考原始论文。
2. Designing Network Design Spaces
这篇论文提出了一种结合了手工设计和 NAS 各自优点的网络设计范式:不再专注于设计单个网络实例,而是设计参数化的网络群体的设计空间 (design design space) 。具体而已,就是从一个受限很小的初始设计空间开始,逐渐添加(参数化的)设计要素,并从新的设计空间中采样评估,迭代优化直到最后得到的设计空间满足要求。
这里设计空间抽象成满足参数化设计要素的模型分布,接着就可以对其采样,并利用统计方法来推断设计空间的性质。文中主要借用误差经验分布函数 (EDF) 来评估设计空间的优劣,其给出了从设计空间采样的 n 个模型中误差小于 e 的比例:
\[F(e)=\frac{1}{n} \sum_{i=1}^{n} \mathbf{1} \left[e_{i} < e \right].\]
整个 design design space 过程可总结下面的步骤:
- 对设计空间的模型进行采样和训练而获得的模型分布。
- 计算和绘制误差 EDF 以总结设计空间质量。
- 将设计空间的各种属性可视化,并使用经验自助法来获得洞悉。
- 利用这些见解来完善设计空间。
利用上述设计方法,论文在 low-compute, low-epoch 的训练配置区间上得到了 RegNet 设计空间。其中发现的最有意思的一条设计要素是每个块的宽度与深度应符合如下线性关系:
\[u_j=w_0+w_a\cdot j\quad\mathrm{for}\quad 0 < j < d,\]
其中 \(d\) 是块的深度,\(w_{0}\) 是初始宽度,\(w_{a}\) 是斜率。
这是我近一两年来开过的最有意思的论文,方法新颖扎实,极力推荐。
3. Revisiting ResNets: Improved Training and Scaling Strategies
近年来,研究者们提出了大量的改进来提升图像识别的性能。这些改进大致体现在四个正交轴上:架构、训练/正则化方法、扩展策略和使用额外的训练数据。这篇文章 (1) 重新回归到基础的 ResNet 架构上,从训练方法和扩展策略上对其进行改进升级,最后使其赶超当前最好的模型。
下面是他们的一些重要的实验发现:
- FLOP 不能准确预测有界数据区域下的性能,且最佳性能扩展策略与训练过程之间有强依赖关系。
- 使用现代训练技术从监督学习中获得的表示在下游计算机视觉任务上与最先进的自监督表示(SimCLR、SimCLRv2)相媲美或优于最先进的自监督表示。
- 减少权重衰减 (weight decay) 和正则化方法 (dropout, stochastic depth, label smoothing, RandAugment) 相结合可以提升模型性能。
关于第一点发现值得细说:在小模型上,误差和 FLOP 之间整体呈幂律趋势,对扩展配置(深度、宽度、图像分辨率)的依赖性很小;在大模型上这种趋势被打断。如下图所示。
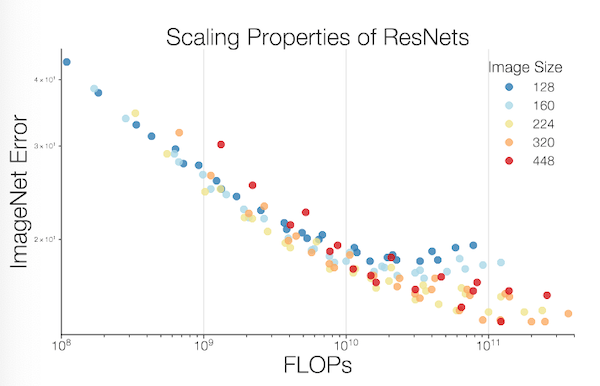
因此确切的扩展配置会对性能产生很大影响,即使在同样数量的 FLOP 下也是如此。另外扩展策略还与训练过程相关。实验发现,在较短的 epoch 训练区间,宽度缩放优于深度缩放;在较长 epoch 区间,深度缩放优于宽度缩放。
基于上述观察,作者提出如下扩展策略:在可能发生过拟合的区间进行深度缩放。这也间接说明了深度网络结构不容易出现过拟合。
最后其改进的模型 (ResNet-RS) 在 TPU 上比 EfficientNets 快 1.7 - 2.7 倍,并在 ImageNet 上获得了 86.2% 的正确率。
4. References
[1] Bello, Irwan and Fedus, William and Du, Xianzhi and Cubuk, Ekin Dogus and Srinivas, Aravind and Lin, Tsung-Yi and Shlens, Jonathon and Zoph, Barret, Revisiting {{ResNets}}: {{Improved Training}} and {{Scaling Strategies}}, 2021.
[2] Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining, A {{ConvNet}} for the 2020s, 2022.
[3] Tan, Mingxing and Le, Quoc, {{EfficientNet}}: {{Rethinking Model Scaling}} for {{Convolutional Neural Networks}}, PMLR, 2019.