DeepSeek LLM 在 2024 年的进展
过年期间被 DeepSeek-V3 和 DeepSeek-R1 刷屏了,趁空闲时间,粗略过一遍 DeepSeek 模型的系列论文和报告。
1. DeepSeek-R1
下面是对论文(1) 的简短总结:
- 推出了两个推理模型:DeepSeek-R1-Zero 和 DeepSeek-R1。
- 其中 DeepSeek-R1-Zero 只经过大规模的 RL 后训练 (无 SFT 后训练) 就自然的涌现出可观的推理能力:自我验证、反射和生成长的 CoT 推理链等。不过该模型有可读性差和语言混淆的问题。
- 在 DeepSeek-R1-Zero 的基础上,在 RL 后训练之前整合多阶段训练和冷启动数据来进一步增强模型的推理能力,得到 DeepSeek-R1 模型,其性能可媲美 OpenAI-o1-1217。
- 文中还探索了把 DeepSeek-R1 的推理知识蒸馏到小模型 (Qwen2.5、Llama) 上,比直接在小模型上应用 RL 后训练。这表明大型基础模型发现的推理模式对于提高推理能力至关重要。而且其蒸馏的 14B 推理模型可以超越当前最好的开源推理模型 QwQ-32B-Preview。值得深入研究的现象。
- DeepSeek-R1 在需要长程上下文理解的任务上表现出出色的性能,大大优于 DeepSeek-V3。
- DeepSeek-R1-Zero 的 RL 后训练只使用了两种基于规则的奖励系统:Accuracy rewards、Format rewards。采用格式奖励模型用于强制模型将其思考过程置于 ’<think>’ 和 ’</think>’ 标签之间。
- DeepSeek-R1-Zero 的 RL 后训练没有采用结果或过程神经奖励模型,因为他们发现神经奖励模型在大规模强化学习过程中可能会遇到奖励黑客的问题,而且重新训练奖励模型需要额外的训练资源,并且使整个训练管道复杂化。
- DeepSeek-R1-Zero 的 RL 后训练会使用一个简单的回答模版用于指导基本模型遵循该模版展示的推理过程进行回答。
- DeepSeek-R1-Zero 通过利用扩展的测试时间计算,自然而然地获得了解决日益复杂的推理任务的能力。这种计算范围从生成数百到数千个推理标记,使模型能够更深入地探索和完善其思维过程。这种自我进化最引人注目的方面之一是随着测试时间计算的增加而出现复杂的行为,比如自省 (reflection) 和探索多个替代方法。
- DeepSeek-R1-Zero 会有顿悟时刻 (Aha Moment) 的现象。“顿悟时刻” 说明 RL 有可能在人工系统中解锁新的智能水平,为未来更加自主和自适应的模型铺平道路。
- 文中也列举了一些失败的尝试:Process Reward Model (PRM)、Monte Carlo Tree Search (MCTS)。其中的讨论非常有洞见。
- 当前 DeepSeek-R1 在函数调用、多轮对话、复杂角色扮演和格式输出等能力上不如 DeepSeek-V3。
- 在评估 DeepSeek-R1 时,观察到它对提示很敏感。Few-Shot 提示始终会降低其性能。推荐使用 Zero-Shot 提示直接描述问题。
为了进一步的提升 DeepSeek-R1-Zero 的推理能力,他们设计了一个四阶段的流水线来训练 DeepSeek-R1:
- Cold Start
- 训练 DeepSeek-R1 时先收集了少量的长 CoT 数据来微调模型,并以微调模型作为初始 RL 参与者。这些 cold start 数据具有可读性和格式要求,这可以有效的缓解 DeepSeek-R1-Zero 中出现的语言混淆问题。
- Reasoning-oriented Reinforcement Learning
- 与 DeepSeek-R1-Zero 的 RL 后训练相同的过程,不过引入了语言一致性奖励来缓解 CoT 中的语言混淆问题。注意这一阶段的 RL 训练只用基于规则的奖励系统。
- Rejection Sampling and Supervised Fine-Tuning
- 当面向推理的 RL 收敛时,他们利用该模型检查点来收集 SFT(监督微调)数据,用于下一轮模型微调。这一阶段中的一些数据通过使用生成奖励模型,将真实和模型预测输入到 DeepSeek-V3 中进行判断。
- Reinforcement Learning for all Scenarios
- 为了进一步使模型与人类偏好保持一致,他们实现了一个二级强化学习阶段,旨在提高模型的有用性和无害性,同时完善其推理能力。具体来说,他们使用奖励信号和各种提示分布的组合来训练模型。
2. DeepSeek-V3
下面是对 DeepSeek-V3 模型 (2) 的技术报告的简短总结:
- 延续了 DeepSeek-V2 的网络结构 (MLA + MoE)。
- 共 671B 参数,每个 Token 激活 37B 参数。
- 用 14.8T Token 进行预训练,接着再进行 SFT 和 RL 后训练。
- 整个训练共用了 2048 块 H800 GPU。花费约 788M H800 GPU 每小时。
- 训练过程非常稳定,中途没有任何不可恢复的损失峰值和训练回滚。
- 采用负载均衡的辅助无损策略 (auxiliary-loss-free strategy) 来缓解因鼓励负载均衡造成的性能下降。
- 采用互补序列平衡损失 (complementary sequence-wise balance loss) 来鼓励保持每个序列的负载平衡。
- 采用了多标记预测 (multi-token prediction) 训练目标,该目标可以提高评估基准的整体性能。
- 将 DeepSeek R1 系列模型的推理能力蒸馏到 DeepSeek-V3 模型中。
- 设计了 DualPipe 算法以实现高效的管道并行性。
- 在预训练后进行了两阶段上下文长度扩展 (two-stage context length extension),32k 到 128k。
- 性能可与 GPT-4o 和 Claude-Sonnet-3.5 等当前领先的闭源模型相媲美。
- 采用混合精度训练框架,大多数计算密度运算都是在 FP8 中进行的,而少数关键运算则战略性地保持其原始数据格式,以平衡训练效率和数值稳定性。
- 在 post-training 的 SFT 微调阶段,用内部的 deepseek-r1 模型来生成 SFT 微调推理数据,用 deepseek-v2 生成其他非推理数据。
- 在 post-training 的 RL 微调阶段,用了一个基于规则的奖励模型和一个基于模型的奖励模型。其中“规则”可以是(数学问题)回答的格式以及(代码生成)代码生成问题的测试用例。
- 同 DeepSeek-v2 一样采用 Group Relative Policy Optimization (GRPO) 强化学习算法。
- 从推理模型中蒸馏知识;LLMs 模型的自奖励。
DeepSeek-V3 最大的突破是其极大缩减了整个训练花销:

3. DeepSeek-V2
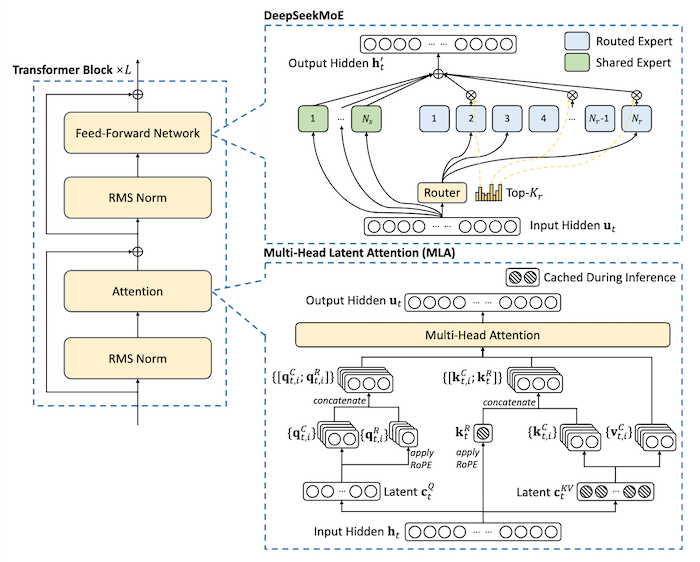
下面是对论文 (3) 的简短总结:
- DeepSeek-V2 采用 MoE 架构,使用 8.1T tokens 多源语料进行训练。其包括 236B 的模型参数,128k tokens 的上下文长度,推理时每个 token 激活 21B 的参数。
- 采用革新的 Multi-head Latent Attention (MLA),通过将键值缓存显著压缩为潜在向量来保证高效推理。克服了传统多头注意力 (MHA) 的键值 缓存对 LLM 的推理效率构成的重大障碍。
- 由于 RoPE 位置编码策略与 MLA 有耦合,会造成 MLA 的高效 KV 缓存策略失效,提出解耦 RoPE 策略,用一个额外的多头 query 和一个共享的 key 来携带 RoPE。
- 使用 SFT 和 RL (GRPO) 进行 Post-Training 对齐。
- 相比 DeepSeek 67B,DeepSeek-V2 减少了 42.5 的训练花销和 93.3% 的 KV 缓存,最多生成吞吐量提升了 5.67 倍。
- 采用专家并行 (expert parallelism),并设计了一种设备受限的路由机制 (Device-Limited Routing),以约束与 MoE 相关的通信成本。
- 采用了三种负载均衡的辅助损失 (Auxiliary Loss for Load Balance):expert-level load balance、device-level load balance 和 communication balance,使模型自动学习路由策略时会考虑负载均衡。
- 增加了更多的中文语料,,并更新了过滤算法,数据质量进一步提升。
- 仍采用 AdamW 优化算法 (β1 = 0.9, β2 = 0.95, and weight_decay = 0.1)。学习率调整策略同 DeepSeek 67B 仍为 warmup-and-step-decay。
- 仍采用自研的 HAI-LLM 框架进行并行训练,HAI-LLM 采用 16 路零气泡 (zero-bubble) 管道并行、8 路专家并行和 ZeRO-1 数据并行。
- 采用 YaRN 方法将默认上下文窗口长度从 4K 扩展到 128K。
- DeepSeek-V2 性能超越 LLaMA3。
- 发现对推理数据的 RL 的后训练与一般数据训练不同的独特特征。因此,其采用了两阶段的 RL 训练策略,首先进行推理对齐,然后进行人类偏好对齐。另外 RL 后训练采用了多个不同的奖励网络。
- 在 SFT 后训练上,如果使用的数据少于 10K,会有性能的显著下降。
4. DeepSeek-V1
下面是对这篇论文 (4) 的主要结果的简单总结:
- 提供了 DeepSeek 7B 和 DeepSeek 76B 两个模型,其中 76B 模型可以与当时的 LLaMA-2 70B 和 GPT-3.5 相媲美。
- 对数据进行三阶段处理:重复数据删除、过滤和重新混合。这种三阶段数据预处理旨在实现更加平衡和包容的数据集,确保充分代表不同的观点和信息。
- 分词采用 Byte-level Byte-Pair Encoding (BBPE) 算法,模型的 vocabulary size 为 102400。
- 模型微观结构借鉴了 LLaMA 的相关设计:RMSNorm、SwiGLU、Rotary Positional Encoding (RoPE)、GroupedQuery Attention (GQA)。宏观结构稍微不同,采用了更深的网络结构设计。
- 超参数:网络以 0.006 的标准差进行初始化、AdamW (β1 = 0.9, β2 = 0.95, and weight_decay = 0.1)、多步学习率调度器。
- 模拟了计算预算 C 与最佳批量大小和学习率之间的幂律关系,称之为超参数的缩放定律,为确定最佳超参数提供了一个经验框架。
- 发现数据质量显着影响最佳模型/数据缩放分配策略。数据质量越高,应为模型扩展分配更多的计算预算。这意味着在相同的数据规模下,高质量的数据可以驱动更大模型的训练。
- 采用 non-embedding FLOPs/token M 来表示模型规模,得到更加正确和简单的最优模型/数据扩展分配策略,且对大规模模型的泛化损失有更好预测。
- 采用 SFT 和 DPO 方法进行 LLM 对齐。并发现 DPO 可以增强模型的开放式生成技能。
5. DeepSeekMoE
这篇论文 (5) 指出当前的 MoE 架构,比如 GShard 可能存在 knowledge hybridity 和 knowledge redundancy 的问题:
- Knowledge Hybridity
- 当前的 MoE 实践采用有限数量的专家,分配给特定专家的 Tokens 可能会涵盖不同的知识。指定的专家将打算在其参数中收集大量不同类型的知识,这些知识很难同时利用。
- Knowledge Redundancy
- 分配给不同专家的 Tokens 可能需要常识。多个专家可能会学得各自的共享知识,从而导致专家参数的冗余。
该文提出 DeepSeekMoE 架构来缓解上述问题,其包含两个核心策略:
- Fine-Grained Expert Segmentation
- 在保持参数数量不变的同时,通过拆分 FFN 中间隐藏维度将专家分为更精细的粒度,并激活了更多细粒度的专家,以实现更灵活和适应性更强的已激活专家组合。
- Shared Expert Isolation
- 分离出某些专家作为共享专家,这些专家始终处于激活状态,旨在在不同环境中捕获和整合共同知识。
DeepSeekMoE 采用 MoE 层代替 FFNs 层来实现 MoE LLMs 的典型方法。MoE 层由多个 Expert 组成,其中每个 Expert 在结构上与标准 FFN 相同。
6. DeepSeekMath
下面是对论文 (6) 的简短总结:
- 从 Common Crawl (CC) 中提取了 120B tokens 的高质量的数学训练语料。
- 用于 Math Pre-Training 的基模型是 DeepSeek-Coder-Base-v1.5 7B。他们发现从代码训练模型开始比从通用大模型开始更好,并且数学训练也能增强模型的其它一般推理能力。结果模型 DeepSeekMath-Base 已经可以和闭源的 Minerva 540B 相媲美,并超越当前的所有开源模型。
- 在 Pre-Training 后再对 DeepSeekMath-Base 做了数学的指令微调:CoT、program-of-thought (PoT)、tool-integrated reasoning。结果模型 DeepSeekMath-Instruct 7B 已经可以与当前 70B 的开源模型相媲美了。
- 数学指令微调后,再接 RL 后训练。他们引入了 GRPO 算法,一种 PPO 算法的变体,不同在于其放弃了批评者模型,而是根据小组分数估计基线,从而显著减少训练资源。
- 在 GRPO 的训练阶段,同时使用了基于结果和过程的奖励模型,并且奖励模型也一直迭代持续学习。
- 在实验中,他们将奖励函数分为 ’Rule’ 和 ’Model’。Rule 是指根据答案的正确性来判断响应的质量,Model 表示我们训练一个奖励模型来对每个响应进行评分。
- 这篇论文中首次提出了 GRPO,包含了该算法的很多细节,这部分内容非常值得细读。该算法也用于后面的 DeepSeek-V3、DeepSeek-R1 模型的训练。
文中提供了一个统一的范式来分析不同的训练方法: SFT、RFT、DPO、PPO、GRPO。非常有洞见。具体而已,这些训练方法可以统一在下面的公式里:
\[\nabla_\theta\mathcal{J}_{\mathcal{A}}(\theta)=\mathbb{E}[\underbrace{(q,o)\sim\mathcal{D}}_{Data\mathrm{~Source}}]\left(\frac{1}{|o|}\sum_{t=1}^{|o|}\underbrace{GC_{\mathcal{A}}(q,o,t,\pi_{rf})}_{Gradient\mathrm{~Coe}fficient}\nabla_\theta\log\pi_\theta(o_t|q,o_{\lt t})\right).\]
其中 \(\mathcal{D}\) 表示数据源, \(\mathcal{A}\) 表示具体算法,GC 表示梯度系数。论文及其附录中包含更详细的内容。
这篇论文对理解后面的 DeepSeek-R1 具有非常重要的参考价值,尤其是其关于 RL 算法和模型推理方向上的探索与分析。
7. DeepSeek-Coder
这是对技术报告 (7) 的简短总结:
- 引入了 DeepSeek-Coder-Base 和 DeepSeek-Coder-Instruct 模型,包含 1.3B 到 33B 一系列模型,从 2T tokens 包含 87 中语言的语料从头训练。
- 在存储库级别组织预训练数据,以增强预训练模型在存储库内跨文件上下文中的理解能力。
- 除了在预训练期间采用下一个符号预测损失 (next token prediction loss) 外,还采用了 Fill-In-Middle (FIM) 方法。这种方法旨在进一步增强模型的代码完成功能。
- 为了满足处理较长代码输入的要求,上下文长度扩展到 16K。
- 当前的代码大模型主要用文件级的源码进行预训练,忽略了项目中源码文件之间的依赖。DeepSeek-Coder 考虑了代码仓库中文件的依赖关系,并尽可能的在仓库级上进行预训练。
8. 参考文献
[1] {DeepSeek Team}, {{DeepSeek-R1}}: {{Incentivizing Reasoning Capability}} in {{LLMs}} via {{Reinforcement Learning}}, 2025.
[2] {DeepSeek Team}, {{DeepSeek-V3 Technical Report}}, 2024.
[3] {DeepSeek Team}, {{DeepSeek-V2}}: {{A Strong}}, {{Economical}}, and {{Efficient Mixture-of-Experts Language Model}}, 2024.
[4] {DeepSeek Team}, {{DeepSeek LLM}}: {{Scaling Open-Source Language Models}} with {{Longtermism}}, 2024.
[5] {DeepSeek Team}, {{DeepSeekMoE}}: {{Towards Ultimate Expert Specialization}} in {{Mixture-of-Experts Language Models}}, Association for Computational Linguistics, 2024.
[6] {DeepSeek Team}, {{DeepSeekMath}}: {{Pushing}} the {{Limits}} of {{Mathematical Reasoning}} in {{Open Language Models}}, 2024.
[7] {DeepSeek Team}, {{DeepSeek-Coder}}: {{When}} the {{Large Language Model Meets Programming}} – {{The Rise}} of {{Code Intelligence}}, 2024.